
前言
“一个网站有 20 亿 url 存在一个黑名单中,这个黑名单要怎么存?若此时随便输入一个 url,你如何快速判断该 url 是否在这个黑名单中?并且需在给定内存空间(比如:500M)内快速判断出。” 这是一道经常在面试中出现的算法题。
很多人脑海中首先想到的可能是 HashSet,因为 HashSet 的底层是采用 HashMap 实现的,理论上时间复杂度为:O(1)。达到了快速的目的,但是空间复杂度呢?URL 字符串通过 Hash 得到一个 Integer 的值,Integer 占 4 个字节,那 20 亿个 URL 理论上需要:4 字节 (byte) * 20 亿 = 80 亿 (byte) ≈ 7.45G 的内存空间,不满足空间复杂度的要求。
还有一种方法就是位图法[1],每个 URL 取整数哈希值,置于位图相应的位置上,看上去是可行的。但位图适合对海量的、取值分布很均匀的集合去重。位图法的所占空间随集合内最大元素的增大而增大,即空间复杂度随集合内最大元素增大而线性增大。要设计冲突率很低的哈希函数,势必要增加哈希值的取值范围,4G 的位图最大值是 320 亿左右,为 50 亿条 URL 设计冲突率很低、最大值为 320 亿的哈希函数比较困难。这就会带来一个问题,如果查找的元素数量少但其中某个元素的值很大,比如数字范围是 1 到 1000 亿,那消耗的空间不容乐观。因此,出于性能和内存占用的考虑,在这里使用布隆过滤器才是最好的解决方案:布隆过滤器是对位图的一种改进。
这里就引出本文要介绍的 “布隆过滤器”。
Bloom Filter 概述
布隆过滤器(Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
Bloom Filter 原理
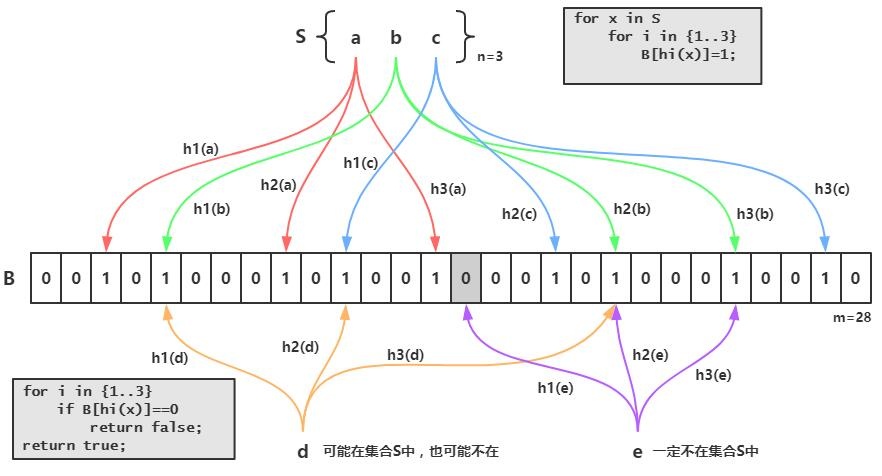
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter 跟单哈希函数 Bit-Map 不同之处在于:Bloom Filter 使用了 k 个哈希函数,每个字符串跟 k 个 bit 对应,从而降低了冲突的概率。
应用场景
主要是解决大规模数据下不需要精确过滤的场景。
- 检查垃圾邮件地址:如果用哈希表,每存储一亿个 email 地址,就需要 1.6GB 的内存(用哈希表实现的具体办法是将每一个 email 地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email 地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB 的内存。而 Bloom Filter 只需要哈希表 1/8 到 1/4 的大小就能解决同样的问题。布隆过滤器决不会漏掉任何一个在黑名单中的可疑地址。至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能被误判的清白邮件地址。
- 解决缓存穿透:缓存穿透,是指查询一个数据库中不一定存在的数据。正常情况下,查询先进行缓存查询,如果 key 不存在或者 key 已经过期,再对数据库进行查询,并将查询到的对象放进缓存。如果每次都查询一个数据库中不存在的 key,由于缓存中没有数据,每次都会去查询数据库,很可能会对数据库造成影响。缓存穿透的一种解决办法是为不存在的 key 缓存一个空值,直接在缓存层返回。这样做的弊端就是缓存太多空值占用了太多额外的空间,这点可以通过给缓存层空值设立一个较短的过期时间来解决。另一种解决办法就是使用布隆过滤器,查询一个 key 时,先使用布隆过滤器进行过滤,如果判断请求查询 key 值存在,则继续查询数据库;如果判断请求查询不存在,直接丢弃。
- Key-Value 缓存系统的 Key 校验:在很多 Key-Value 系统中也使用了布隆过滤器来加快查询过程,如 Hbase,Accumulo,Leveldb,一般而言,Value 保存在磁盘中,访问磁盘需要花费大量时间,然而使用布隆过滤器可以快速判断某个 Key 对应的 Value 是否存在,因此可以避免很多不必要的磁盘 IO 操作,只是引入布隆过滤器会带来一定的内存消耗。
- Google 的 BigTable:Google 的 BigTable 也使用了布隆过滤器,以减少不存在的行或列在磁盘上的 I/O。
- 新闻客户端推荐系统:推荐系统给用户推荐新闻,避免重复推送。
- 爬虫 URL 地址去重:爬虫时判断某个 URL 是否已经被爬取过。
- 单词拼写检查
- 黑名单过滤
- …
代码实现
HashSet 实现
利用 HashSet 实现黑名单过滤,写入和判断元素是否存在都有对应的 API,所以实现起来也比较简单。
通过单元测试演示 HashSet 实现黑名单过滤功能;同时为了前后的对比将堆内存写死(-Xms64m -Xmx64m),为了方便调试加入了 GC 日志的打印(-XX:+PrintHeapAtGC),以及内存溢出后 Dump 内存(-XX:+HeapDumpOnOutOfMemoryError)。
1 | -Xms64m -Xmx64m -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError |
1、写入 100 条数据时:
1 | @Test |
2、写入 1000 W 条数据时:
1 | @Test |
执行后马上就内存溢出,可见在内存有限的情况下我们不能使用这种方式。
Guava 中的布隆过滤器
BloomFilter 实现的一个重点就是怎么利用 hash 函数把数据映射到 bit 数组中。Guava 的实现是对元素通过 MurmurHash3 计算 hash 值,将得到的 hash 值取高 8 个字节以及低 8 个字节进行计算,以得当前元素在 bit 数组中对应的多个位置。
Guava 会通过你预计的数量以及误报率帮你计算出你应当会使用的数组大小 numBits 以及需要计算几次 Hash 函数 numHashFunctions 。
1、组件依赖:通过 Maven 引入 Guava 开源组件,在 pom.xml 文件加入下面的代码:
1 | <dependency> |
2、代码实现:通过 Java 代码实现布隆过滤器
1 | @Test |
代码分析:我们的定义了一个预期数据量为 1000 W、预期误判率为 0.001 的布隆过滤器,接下来向布隆过滤器中插入了 0-10000000 数据,然后用 0- 10000000 以及 10000000-20000000 数据来测试误判率。
(1)经过测试:“预期数据量:10000000,判断数量:10000000,预期误判率:0.001,存在比率:1.0 ”,可发现当过滤器判断 0-10000000 的数据时,存在比率为 1.0,即布隆过滤器对于已经见过的元素肯定不会误判,它只会误判那些没见过的元素。
(2)经过测试:“预期数据量:10000000,误判数量:10132,预期误判率:0.001,实际误判率:0.0010132” ,符合预期误判率:0.001。
Redis 中的布隆过滤器
安装 Rebloom 插件
1、安装 Rebloom 插件:Redis 安装在这里就不介绍了,这里讲一下 Rebloom 插件安装。
1 | // 下载 Rebloom 源文件 |
2、加载 Rebloom 插件方法
(1)、在启动的 client 中使用 MODULE LOAD 命令去加载(重启 Redis 后失效)
1 | MODULE LOAD /usr/lib64/redis/modules/rebloom/redisbloom.so |
(2)、命令行加载 Rebloom 插件
1 | /usr/bin/redis-server /etc/redis.conf --loadmodule /usr/lib64/redis/modules/rebloom/redisbloom.so |
(3)、在 redis.conf 文件中加入配置信息
1 | loadmodule /usr/lib64/redis/modules/rebloom/redisbloom.so |
3、通过命令测试 Redis Bloom Filter
1 | // 创建一个空的布隆过滤器,并设置一个期望的错误率和初始大小。 |
通过 Java 代码实现布隆过滤器
1、组件依赖:通过 Maven 引入 Redisson [2]开源组件,在 pom.xml 文件加入下面的代码:
1 | <dependency> |
2、代码实现:通过 Java 代码实现布隆过滤器
1 | @Test |
代码分析:Redisson 利用 Redis 实现了 Java 分布式布隆过滤器(Bloom Filter),通过 RedissonClient 初始化布隆过滤器,预计统计元素数量为 10000,期望误差率为 0.001。“预期数据量:10000,误判数量:51,预期误判率:0.001,实际误判率:0.00255 ”。我们看到了误判率大约 0.255%,比预计的 0.1% 高,不过布隆的概率是有误差的,只要不比预计误判率高太多,都是正常现象。
总结
在使用 Bloom Filter 时,绕不过的两点是预估数据量 n 以及期望的误判率 fpp,在实现 Bloom Filter 时,绕不过的两点就是 hash 函数的选取以及 bit 数组的大小。
期望的误判率越低,需要的空间越大。预估数据量,当实际数量超出这个数值时,误判率会上升。因此用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出估计值很多导致误判率升高。
布隆过滤器的空间占用有一个简单的计算公式,但是推导比较繁琐,这里就省去推导过程了,感兴趣的读者可以点击「延伸阅读」深入理解公式的推导过程。虽然存在布隆过滤器的空间占用的计算公司,但是有很多现成的网站已经支持计算空间占用的功能了,我们只要把参数输进去,就可以直接看到结果,比如 布隆计算器。
延伸阅读
- 布隆过滤器 (Bloom Filter) 详解:详解布隆过滤器的相关算法和参数设计。
- Murmur 哈希:Murmur 哈希,于 2008 年被发明。这个算法 hbase、redis、kafka 都在使用。
- Counting Bloom Filter:要实现删除元素,可以采用 Counting Bloom Filter。它将标准布隆过滤器位图的每一位扩展为一个小的计数器 (Counter),插入元素时将对应的 k 个 Counter 的值分别加 1,删除元素时则分别减 1。
- 布谷鸟过滤器:为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。相比布谷鸟过滤器而言布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数。
参考博文
[1]. 如何判断一个元素在亿级数据中是否存在?
[2]. 大数据量下的集合过滤—Bloom Filter
[3]. 布隆过滤器 (Bloom Filter) 的原理、实现和探究
注脚
[1]. 位图法:位图法就是 BitMap 的缩写,所谓 BitMap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。
[2]. Redisson:
Redisson 在基于 NIO 的 Netty 框架上,充分的利用了 Redis 键值数据库提供的一系列优势,在 Java 实用工具包中常用接口的基础上,为使用者提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间的协作。

