
前言
在 Redis 系列的开篇文章中,我们对 Redis 概述以及 Redis 数据结构与对象进行了详细的讨论以及了解。经过上一篇文章的阅读,相信读者已经对 Redis 的内部结构有了大致了解,接下来我们继续深入了解 Redis 内部结构。
对于 Redis,相信大家对 “Redis 的持久化有哪几种方式?”、“Redis 的数据淘汰机制?” 、“Redis 的过期键淘汰策略?” 、“Redis 订阅与发布机制? ”、“Redis 主从复制的原理?” 等面试题目都不陌生,那么本文就从常见的 Redis 面试题目出发,带领大家深入了解 Redis。
Redis 数据库结构?
服务器中的数据库
Redis 服务器将所有数据库都保存在服务器状态 redis.h/redisServer 结构的 db 数组中,db 数据的每一项都是一个 redis.h/redisDb 结构,每个 redisDb 结构代表一个数据库:
1 | struct redisServer { |
在初始化服务器时,程序会根据服务器状态的 dbnum 属性来决定应该创建多少个数据库,dbnum 属性的值由服务器配置的 database 选项决定,默认情况下,该选项的值为 16。默认情况下,Redis 客户端的目标数据库为 0 号数据库。
在服务器内部,客户端状态 redisClient 结构的 db 属性记录了客户端当前的目标数据库,这个属性是一个指向 redisDb 结构的指针:
1 | struct redisClient { |
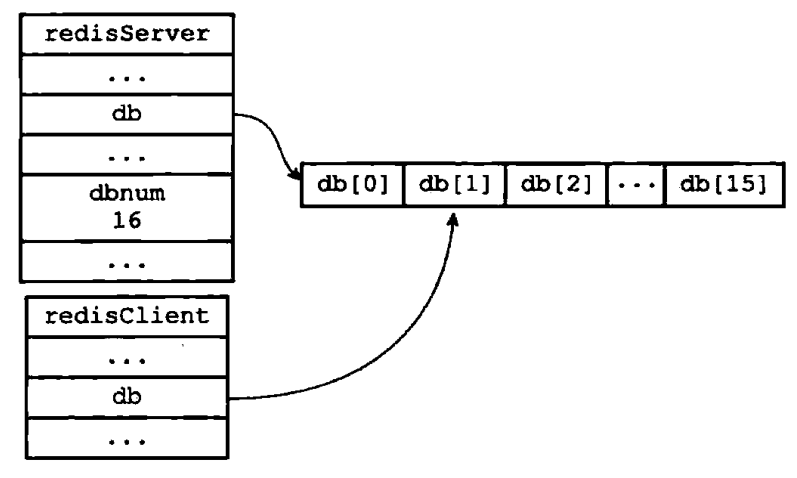
客户端通过修改目标数据库指针,让它指向 redisServer.db 数组中的不同元素来切换不同的数据库。
数据库键空间
Redis 是一个键值对(key-value pair)数据库服务器,服务器中的每个数据库都由一个 redis.h/redisDb 结构表示,数据库主要由 dict 和 expires 两个字典构成,其中,redisDb 结构的 dict 字典保存了数据库中的所有键值对,我们将这个字典称为键空间(key space);而 expires 字典保存了数据库中的键的过期时间:
1 | typedef struct reddisDb { |
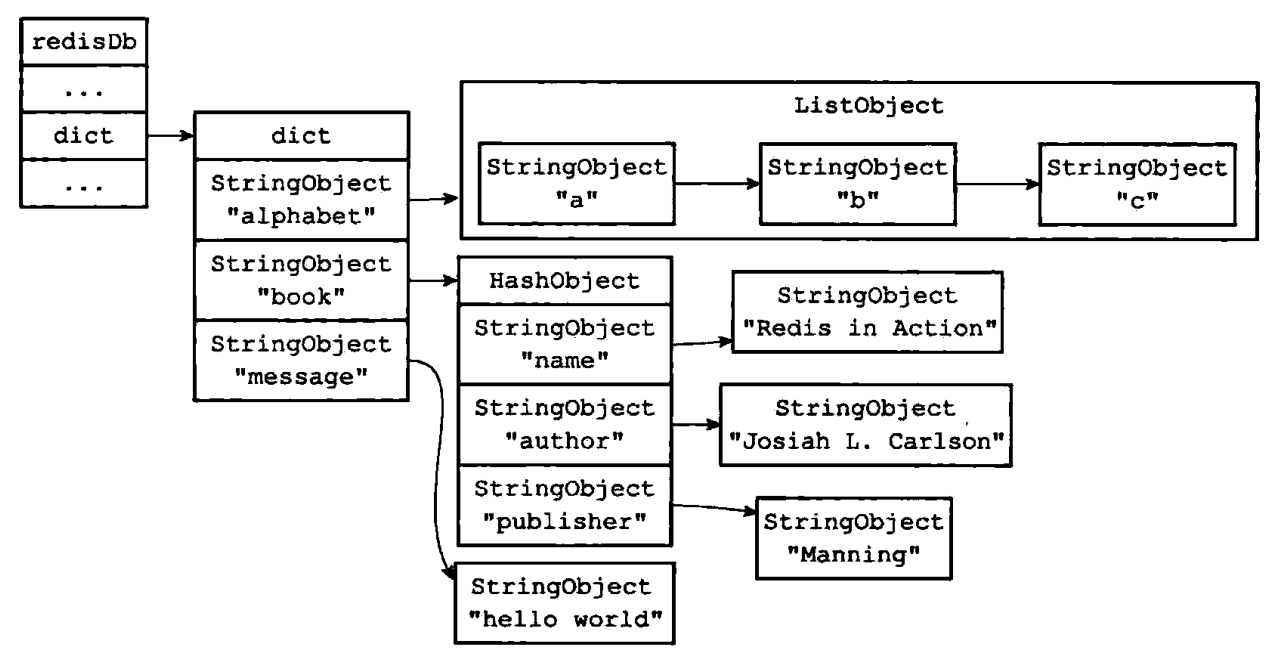
因为数据库的键空间是一个字典,所以所有针对数据库的操作,比如添加一个键值对到数据库,或者从数据库中删除一个键值对,又或者在数据库中获取某个键值对等,实际上都是通过键空间字段进行操作来实现的。
当使用 Redis 命令对数据库进行读写时,服务器不仅会对键空间执行指定的读写操作,还会执行一些额外的维护操作,其中包括:
- 在读取一个键之后(读操作和写操作都要对键进行读取),服务器会根据键是否存在来更新服务器的键空间命中(hit)次数或者键空间不命中(miss)次数,这两个值可以在 INFO stats 命令的 keyspace_hits 属性和 keyspace_misses 属性中查看。
- 在读取一个键之后,服务器会更新键的 LRU(最后一次使用)时间,这个值可以用于计算键的闲置时间,使用 OBJECT idletime <key> 命令可以查看键 key 的闲置时间。
- 如果服务器在读取一个键时发现该键已经过期,那么服务器会先删除这个过期键,然后才执行余下的其它操作。
- 如果有客户端使用 WATCH 命令监视了某个键,那么服务器在对被监视的键进行修改之后,会将这个键标记为脏(dirty),从而让事物程序注意到这个键已经被修改过。
- 服务器每次修改一个键之后,都会对脏(dirty)键计数器的值增 1,这个计数器会触发服务器的持久化以及复制操作。
- 如果服务器开启了数据库通知功能,那么在对键进行修改之后,服务器将按配置发送相应的数据库通知。
Redis 的过期键淘汰策略?
过期时间
设置键的生存时间或者过期时间
通过 EXPIRE 命令或者 PEXPIRE 命令,客户端可以以秒或者毫秒精度为数据库中的某个键设置生存时间(Time To Live,TTL),在经过指定的秒数或者毫秒数之后,服务器就会自动删除生存时间为 0 的键。
与 EXPIRE 命令和 PEXPIRE 命令类似,客户端可以通过 EXPIREAT 命令或者 PEXPIREAT 命令,以秒或者毫秒精度给数据库中的某个键设置过期时间(expire time)。
虽然有多种不同单位和不同形式的设置命令,但实际上 EXPIRE、PEXPIRE、EXPIREAT 三个命令都是使用 PEXPIREAT 命令来实现的:无论客户端执行的是以上四个命令中的哪一个,经过转换之后,最终的执行效果都和执行 PEXPIREAT 命令一样。
保存过期时间
redisDb 结构的 expires 字典保存了数据中所有键的过期时间,我们称这个字典为过期字典:
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象(也即是某个数据库键)。
- 过期字典的值是一个 long 类型的整数,这个整数保存了键所指向的数据库键的过期时间——一个毫秒精度的 UNIX 时间戳。
1 | typedef struct redisDb { |
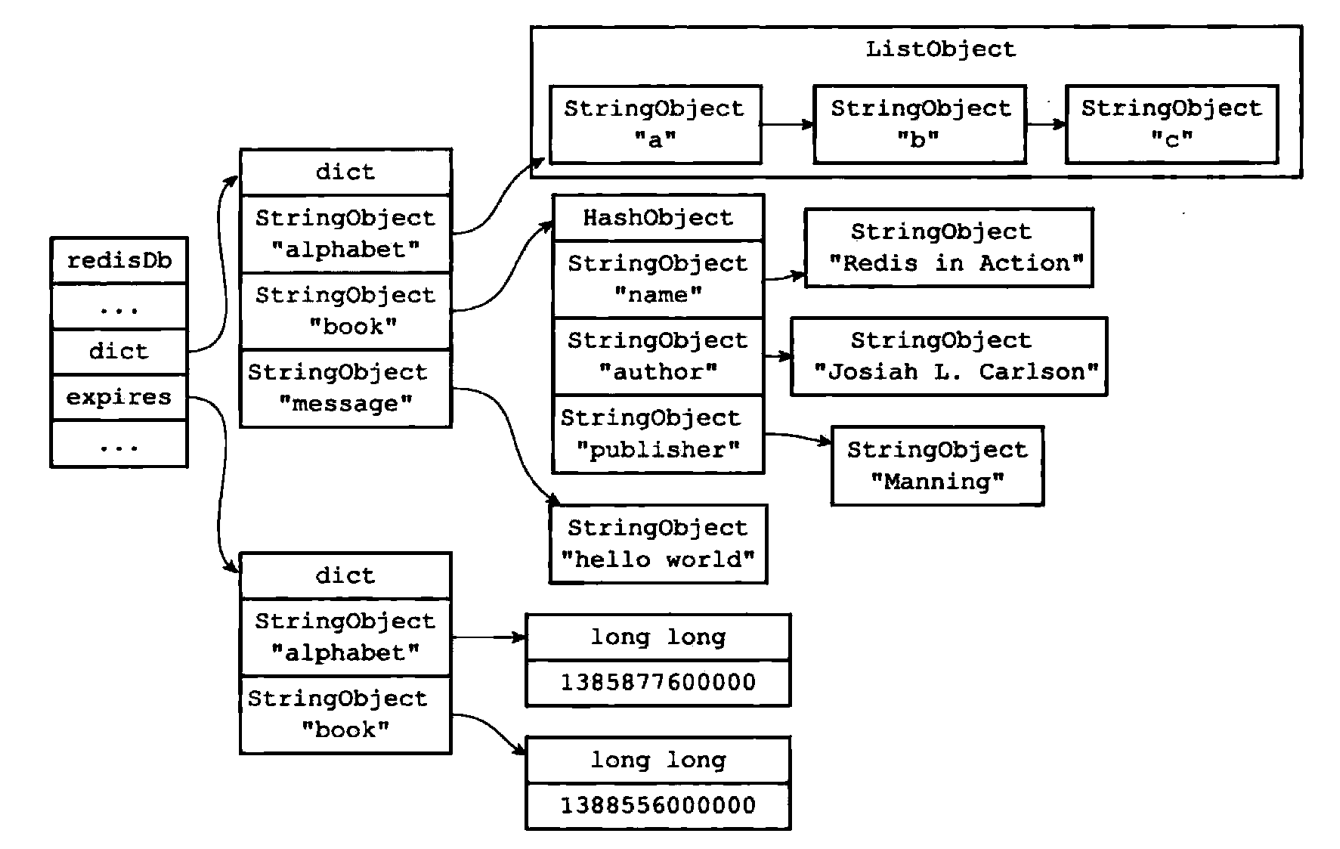
过期键删除策略
定时删除
在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来临时,立即执行对键的删除操作。(主动删除)
优点:对内存是最友好的,通过使用定时器,定时删除策略可以保证过期键会尽可能快地被删除,并释放过期键所占用的内存。
缺点:对 CPU 时间是最不友好的,在过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分的 CPU 时间,在内存不紧张但是 CPU 时间非常紧张的情况下,将 CPU 时间用在删除和当前任务无关的过期键上,无疑会对服务器的相应时间和吞吐量造成影响。
惰性删除
放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。(被动删除)
优点:对 CPU 时间来说是最友好的,程序只会在取出键时才对键进行过期检查,这可以保证删除过期键的操作只会在非做不可的情况下进行,并且删除的目标仅限于当前处理的键,这个策略不会在删除其他无关的过期键上花费任何 CPU 时间。
缺点:对内存不友好,如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期不被删除,它所占用的内存就不会释放。
定期删除
每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。(主动删除)
优点:定期删除策略是定时删除和惰性删除两种策略的一种整合和折中,通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响;通过定期删除过期键,有效减少了因为过期键而带来的内存浪费。
缺点:定期删除策略的难点是确定删除操作执行的时长和频率,如果删除操作执行得太频繁或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将 CPU 时间过多地消耗在删除过期键上面;如果删除操作执行的得太少或者执行得时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。
Redis 的过期键删除策略
Redis 服务器实际使用的是惰性删除和定期删除两种策略(定期删除是集中处理,惰性删除是零散处理):通过配合使用这两种删除策略,服务器可以很好地合理使用 CPU 时间和避免浪费内存空间之间取得平衡
惰性删除策略的实现:过期键的惰性删除策略由 db.c/expireIfNeeded 函数实现,所有读写数据库的 Redis 命令在执行之前都会调用 expireIfNeeded 函数对输入键进行检查。expireIfNeeded 函数就像一个过滤器,它可以在命令真正执行之前,过滤掉过期的输入键,从而避免命令接触到过期键。
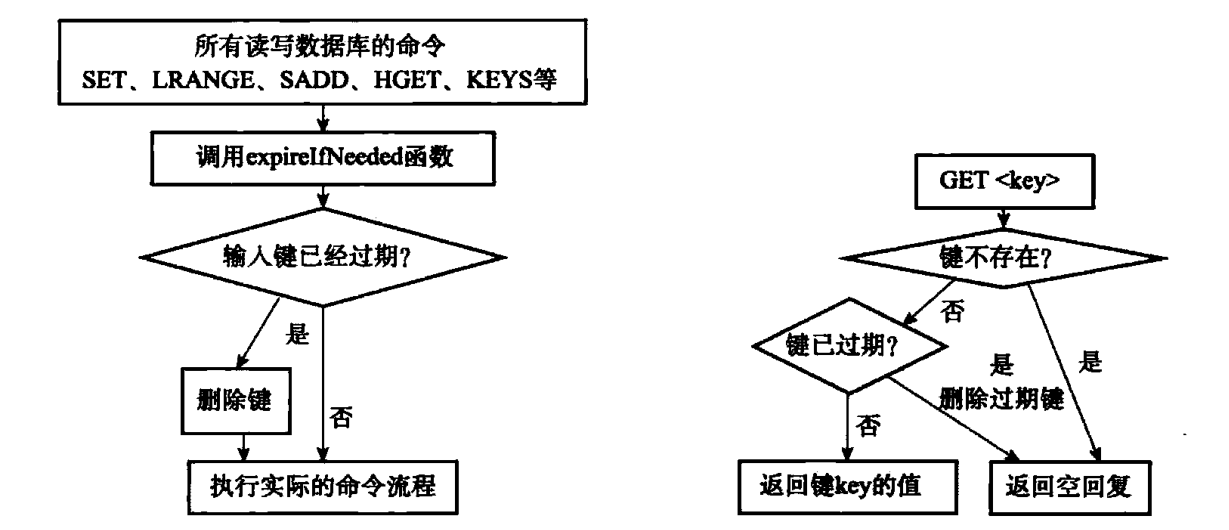
定期删除策略的实现:过期键的定期删除策略由 redis.c/activeExpireCycle 函数实现,每当 Redis 的服务器周期性操作 redis.c/serverCron 函数执行时,activeExpireCycle 函数就会被调用,它在规定的时间内,分多次遍历服务器中的各个数据库(默认每次检查的数据库数量为 16),从数据库的 expire 字典中随机检查一部分键(默认每个数据库检查的键数量为 20)的过期时间,并删除其中的过期键。
AOF、RDB 和复制功能对过期键的处理
- 执行 SAVE 命令或者 BGSAVE 命令所产生的新 RDB 文件不会包含已经过期的键。
- 执行 BGREWRITEAOF 命令所产生的重写 AOF 文件不会包含已经过期的键。
- 当一个过期键被删除之后,服务器会追加一条 DEL 命令到现有 AOF 文件的末尾,显式地删除过期键。
- 当主服务器删除一个过期键之后,它会向所有从服务器发送一条 DEL 命令,显式地删除过期键。
- 从服务器即使发现过期键也不会自作主张地删除它,而是等待主节点发来 DEL 命令,这种统一、中心化的过期键删除策略可以保证主从服务器数据的一致性。
- 当 Redis 命令对数据库进行修改之后,服务器会根据配置向客户端发送数据库通知。
Redis 的数据淘汰机制?
Redis 配置文件中可以使用 maxmemory<bytes> 将内存使用限制设置为指定的字节数。当达到内存限制时,Redis 会根据选择的淘汰策略来删除键。这样可以减少内存紧张的情况,由此获取更为稳健的服务。Redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
Redis 中当内存超过限制时,按照配置的策略,淘汰掉相应的 kv,使得内存可以继续留有足够的空间保存新的数据。Redis 确定驱逐某个键值对后,会删除这个数据,并将这个数据变更消息发布到本地(AOF 持久化)和从机(主从连接)。
缓存淘汰算法
FIFO(First In First Out,先进先出算法) 一种比较容易实现的算法。它的思想是先进先出(FIFO,队列),这是最简单、最公平的一种思想,即如果一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。空间满的时候,最先进入的数据最先被置换(淘汰)。
LRU(Least Recently Used, 最近最少使用算法 )是一种常见的缓存算法,在很多分布式缓存系统(如 Redis、Memcached)中都有广泛使用。LRU 算法的思想是:如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被置换(淘汰)。
LFU(Least Frequently Used , 最不经常使用算法)也是一种常见的缓存算法。LFU 算法的思想是:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被置换(淘汰)。
Redis 提供 6 种数据淘汰策略
我们在该系列的上一篇文章中了解到,redisobject 中除了 type、encoding、ptr 和 refcount 属性外,还有一个 lru 属性用来计算空转时长。OBJECT IDLETIME 命令可以打印出给定键的空转时长,是用当前时间减去键的 lru 时间计算得出的。OBJECT IDLETIME 命令是特殊的,这个命令在访问键的对象时,不会修改值对象的 lru 属性。
键的空转时长还有一个作用,如果服务器打开了 maxmemory 选项,并且服务器用于回收内存的算法是 volatile-lru 或者 allkeys-lru,那么当服务器占用的内存数超过了 maxmemory 选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。
- volatile-lru : 从已设置过期时间的数据集 (server.db[i].expires) 中挑选最近最少使用的数据淘汰。(推荐)
- volatile-ttl : 从已设置过期时间的数据集 (server.db[i].expires) 中挑选将要过期的数据淘汰。
- volatile-random : 从已设置过期时间的数据集 (server.db[i].expires) 中任意选择数据淘汰。
- allkeys-lru : 从数据集 (server.db[i].dict) 中挑选最近最少使用的数据淘汰。(一般推荐)
- allkeys-random : 从数据集 (server.db[i].dict) 中任意选择数据淘汰。
- no-enviction:不会继续服务写请求 (DEL 请求可以继续服务),读请求可以继续进行。这样可以保证不会丢失数据,但是会让线上的业务不能持续进行。(默认)
Redis 4.0 版本后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集 (server.db[i].expires) 中挑选最不经常使用的数据淘汰。
- allkeys-lfu:从数据集 (server.db[i].dict) 中挑选最不经常使用的数据淘汰。
在 Redis 中 LRU 算法是一个近似算法,默认情况下,Redis 随机挑选 5 个键,并且从中选取一个最近最久未使用的 key 进行淘汰,在配置文件中可以通过 maxmemory-samples 的值来设置 redis 需要检查 key 的个数,但是检查的越多,耗费的时间也就越久,结构越精确 (也就是 Redis 从内存中淘汰的对象未使用的时间也就越久),设置多少,综合权衡。
对于具体的数据淘汰机制以及数据淘汰策略,大家可以阅读 Redis 配置文件 redis.conf 中有相关注释。
Redis 的持久化有哪几种方式?
因为 Redis 是内存数据库,它将自己的数据库状态储存在内存里面,所以如果不想办法将储存在内存的数据库状态保存至磁盘里面,那么一旦服务器进程退出,服务器中的数据库状态也会消失不见。
为了解决这个问题,Redis 提供了 RDB(Redis DataBase) 持久化功能,这个功能可以将 Redis 在内存中的数据库状态保存到磁盘里面,避免数据意外丢失。
除了 RDB 持久化功能之外,Redis 还提供了 AOF(Append Only File)持久化功能。与 RDB 持久化通过保存数据库中的键值对来记录数据库状态不同,AOF 持久化是通过保存 Redis 服务器所执行的写命令来记录数据库状态的。
RDB(Redis DataBase)
RDB(Redis DataBase) 是 Redis 默认的持久化方案。在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中。即在指定目录下生成一个 dump.rdb 文件,Redis 重启会通过加载 dump.rdb 文件恢复数据。
RDB 文件是一个经过压缩的二进制文件,由多个部分组成,用于保存和还原 Redis 服务器所有数据库中的所有键值对数据。对于不同类型的键值对,RDB 文件会使用不同的方式来保存它们。

RDB 文件的创建和载入
有两个 Redis 命令可以用于生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE。生成操作会耗费服务器大量的 CPU、内存和磁盘 I/O 资源。
SAVE 命令有服务器进程直接执行保存操作,因此 SAVE 命令会阻塞 Redis 服务器进程,直到 RDB 文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求。
BGSAVE 命令由子进程执行保存操作,BGSAVE 命令会派生(fork)出一个子进程,然后由子进程负责创建 RDB 文件,服务器进程(父进程)继续处理命令请求,所以该命令不会阻塞服务器。
服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
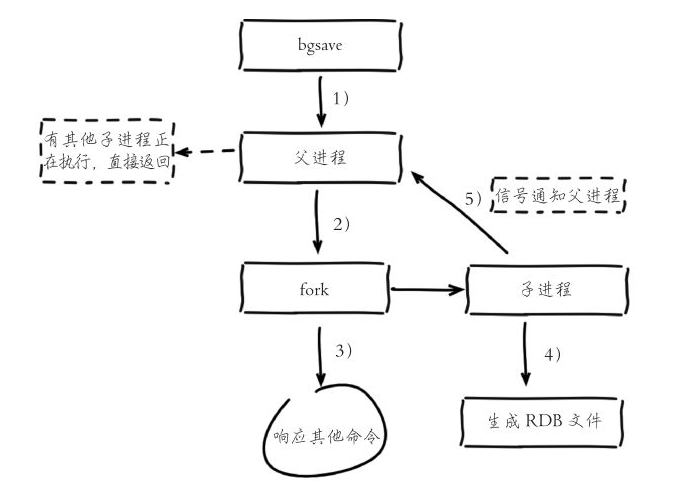
自动间隔性保存
当 Redis 服务器启动时,用户可以通过指定配置文件或者传入启动参数的方式设置 save 选项,如果用户没有主动设置 save 选项,那么服务器就会为 save 选项设置默认条件:
1 | // 服务器在 900 秒(15 分钟)之内,对数据库进行了至少 1 次修改。 |
以上三个条件中的任意一个满足,BGSAVE 命令就会被执行。Redis 的服务器周期性操作函数 serverCron 默认每隔 100 毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查 save 选项所设置的保存条件是否已经满足,如果满足的话,就执行 BGSAVE 命令。
AOF(Append Only File)
AOF(Append Only File)在 Redis 中默认不开启(appendonly no), 默认是每秒将写操作日志追加到 AOF 文件中,它的出现是为了弥补 RDB 的不足(数据的不一致性),所以它采用日志的形式来记录每个写操作,并追加到文件中。Redis 重启的时候会根据日志文件 appendonly.aof 的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF 文件中的所有命令都以 Redis 命令请求协议的格式保存,请求命令会先保存到 AOF 缓冲区里面,之后再定期写入并同步到 AOF 文件。
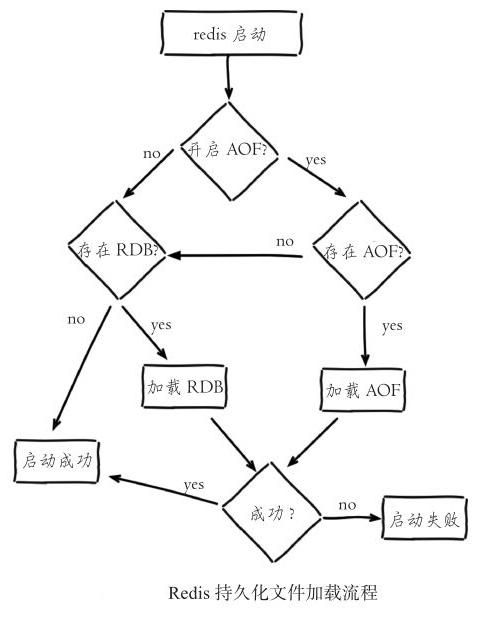
如果服务器开启了 AOF 持久化功能,那么服务器会优先使用 AOF 文件来还原数据库状态。只有在 AOF 持久化功能处于关闭状态时,服务器才会使用 RDB 文件来还原数据库状态。
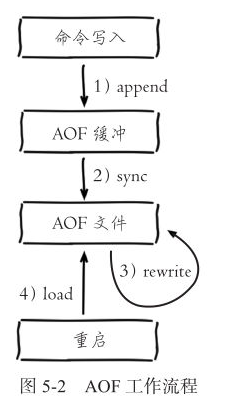
AOF 文件的载入与数据还原
因为 AOF 文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍 AOF 文件里面保存的写命令,就可以还原服务器关闭之前的数据库状态。
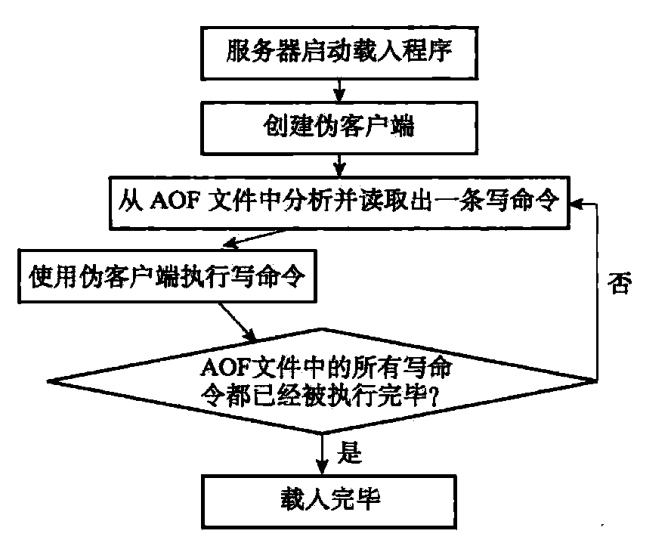
AOF 重写
因为 AOF 持久化是通过保存被执行的写命令来记录数据库状态的,所以随着服务器运行时间的流逝,AOF 文件的体积也会越来越大,如果不加以控制的话,体积过大的 AOF 文件很可能对 Redis 服务器、甚至整个宿主计算机造成影响,并且 AOF 文件的体积越大,使用 AOF 文件来进行数据还原所需的时间就越多。
为了解决 AOF 文件体积膨胀的问题,Redis 提供了 AOF 文件重写(rewrite)功能。AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有的 AOF 文件进行任何读取、分析或者写入操作。通过该功能,Redis 服务器可以创建一个新的 AOF 文件来替代现有的 AOF 文件,新旧两个 AOF 文件所保存的数据库状态相同,但新的 AOF 文件不会包含任何浪费空间的冗余命令,所以新的 AOF 文件的体积通常会比旧的 AOF 文件体积要小得多。
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新的 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点,快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
Redis 订阅(subscribe)与发布(publish)机制?
Redis 的发布和订阅功能由 PUBLIST、SUBSCRIBE、PSUBSCRIBE 等命令组成。通过执行 SUBSCRIBE 命令,客户端可以订阅一个或多个频道,从而你成为这些频道的订阅者(subscriber):每当有其它客户端向被订阅的频道发送消息(message)时,频道的所有订阅者都会收到这条消息。除了订阅频道之外,客户端还可以通过执行 PSUBSCRIBE 命令订阅一个或多个模式,从而成为这些模式的订阅者:每当有其它客户端向某个频道发送消息时,消息不仅会被发送给这个频道的所有订阅者,它还会被发送给所有与这个频道相匹配的模式的订阅者。
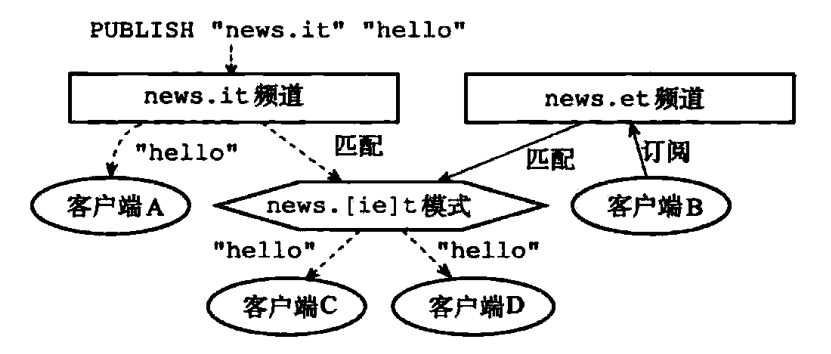
- 服务器状态在 pubsub_channels 字典保存了所有频道的订阅关系, 字典的键为被订阅的频道,字典的值为订阅频道的所有客户端:SUBSCRIBE 命令负责将客户端和被订阅的频道关联到这个字典里面,而 UNSUBSCRIBE 命令则负责解除客户端和被退订频道之间的关联。 当有新消息发送到频道时,程序遍历频道(键)所对应的(值)所有客户端,然后将消息发送到所有订阅频道的客户端上。
- 服务器状态在 pubsub_patterns 链表保存了所有模式的订阅关系,链表的每个节点都保存着一个 pubsubPattern 结构,结构中保存着被订阅的模式,以及订阅该模式的客户端:PSBUSCRIBE 命令负责将客户端和被订阅的模式记录到这个链表中,而 PUNSUBSCRIBE 命令则负责移除客户端和被退订模式在链表中的记录。 程序通过遍历链表来查找某个频道是否和某个模式匹配。
- PUBLISH 命令通过访问 pubsub_channels 字典在向频道的所有订阅者发送消息,通过访问 pubsub_patterns 链表来向所有匹配频道的模式的订阅者发送消息。
- PUBSUB 命令的三个子命令都是通过读取 pubsub_channels 字典和 pubsub_patterns 链表中的信息来实现的。
1 | struct redisServer { |
Redis 主从复制的原理?
在 Redis 中,用户可以通过执行 SLAVEOF 命令或者设置 slaveof 选项,让一个服务器去复制(replicate)另一个服务器,我们称呼被复制的服务器为主服务器(master),而对主服务器进行复制的服务器则称为从服务器(slave)。进行复制的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称作 “数据库状态一致”,或者简称 “一致”。
复制功能的实现
Redis 的复制功能分为同步(sync)和命令传播(command propagate)两个操作:
同步:同步操作用于将服务器的数据库状态更新至主服务器当前所处的数据库状态。
命令传播:命令传播操作则用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致时,让主从服务器的数据库重新回到一致状态。
从服务器对主服务器的同步操作需要通过向主服务器发送 SYNC 命令来完成,以下是 Redis 复制功能的执行步骤:
1) 从服务器向主服务器发送 SYNC 命令。
2) 收到 SYNC 命令的主服务器执行 BGSAVE 命令,在后台生成一个 RDB 文件,并使用一个缓冲区记录从现在开始执行的所有写命令。
3) 当主服务器的 BGSAVE 命令执行完毕时,主服务器会将 BGSAVE 命令生成的 RDB 文件发送给从服务器,从服务器接收并载入这个 RDB 文件,将自己的数据库状态更新至主服务器执行 BGSAVE 命令时的数据库状态。
4) 主服务器将记录在缓冲区里面的所有写命令发给从服务器,从服务器执行这些写命令,将自己的数据库状态更新至主服务器数据库当前所处的状态。
5) 主服务器将自己执行的写命令,也即是造成主从服务器不一致的那条写命令,发给从服务器执行,当从服务器执行了相同的写命令之后,主从服务器将再次回到一致状态。(命令传播)
部分重同步的实现
在 Redis 中,从服务器对主服务器的复制可以分为以下两种情况:
初次复制:从服务器以前没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同。
断线后重复制:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,并继续复制主从服务器。
Redis 2.8 以前的复制功能不能高效地处理断线后重复值情况,但 Redis 2.8 新添加的部分重同步功能可以解决这个问题。部分重同步通过复制偏移量、复制积压缓冲区、服务器运行 ID 三个部分来实现。

在复制操作刚开始的时候,从服务器会成为主服务器的客户端,并通过向主服务器发送命令请求来执行复制步骤,而在复制操作的后期,主从服务器会相互成为对方的客户端(正因为主服务器成为了从服务器的客户端,所以主服务器才可以发送写命令来改变从服务器的数据库状态)。
心跳检测
主服务器通过向从服务器传播命令来更新从服务器的状态,保持主从服务器一致,而从服务器则通过向主服务器发送命令进行心跳检测(默认以每秒一次的频率),以及命令丢失检测。
参考博文
[1]. 《Redis 设计与实现》,第二部分 单机数据库的实现
[2]. 分布式之数据库和缓存双写一致性方案解析
[3]. Redis 配置文件 redis.conf
Redis 深度探险系列
- Redis 深度探险(一):那些绕不过去的 Redis 知识点
- Redis 深度探险(二):Redis 深入之道
- Redis 深度探险(三):Redis 单机环境搭建以及配置说明
- Redis 深度探险(四):Redis 高可用性解决方案之哨兵与集群

